
As some of you might know, I have been promising to provide an intro to XML for a long time. So far, this hasn’t happened yet because I kind of froze up due to perfectionism. Given that I teach XML regularly, there are so many great tutorials out there already and it’s such a fundamental skill in the DH, I panicked. But then I realized: You don’t need a perfect intro, you need a simplistic intro, so you don’t get lost in the clutter. Because despite everything there is to be said about XML in the Digital Humanities, it’s really quite simple and everybody can learn it.
XML really is quite easy to understand, especially to Humanities people. I feel that annotation is a concept most Humanities scholars are familiar with – even when they don’t realize that yet.
Some of the supposedly “gentle” introductions to XML (see resources list below) really are quite long and overwhelming. On the flip side, my boss tends to introduce XML in just one slide. While this may certainly be considered a crash course, in my experience it actually works. That’s why I wanted to provide a super short blog post (ended up being longer than I meant it to be). But because I’m not physically in the same room with you to answer all the questions which come up, I needed to write a few paragraphs after all. However, I think they are really enough to understand XML (although I’m open to feedback if you find that this isn’t the case).
So what is XML?
The eXtensible Markup Language is a text-based data storage format. Its benefits are that it’s very simple – given it’s simple text file based nature – and not very data-intensive, thus ideal for long-term archiving. It further combines machine processability and human readability as a data format.
In the DH, it is especially popular in the context of data standards such as the Text Encoding Initiative (TEI) or others, such as XML-based RDF (Resource Description Framework), LIDO (Lightweight Information Describing Objects) and many others. These are possible because XML really is a meta-language for formulating data standards.
The “eXtensible” stands for “invent your own elements”. Like its well known sibling HTML (the Hypertext Markup Language), XML is historically related to SGML (Standard Generalized Markup Language) which had introduced the principle of the separation of form and content. XML is used to semantically describe data (for long-term archiving and as a “single source”).
If you want to represent said data, the XML family (don’t worry too much about it now) provides methods for transforming this data to, say a website (in HTML) or a printable format (in LaTeX). An option for this are XSLT transformations (see an example in Simple XML to LaTeX Transformation Tutorial or my XSLT video tutorials in German) but that’s not immediately relevant for you at this point.
Right now we only want to learn XML which is really quite simple and opens the door to understanding all those related technologies and also the language of the web, HTML. But that comes later, when you’re ready.
How does it work?
XML is structured in a tree hierarchy, thus the indentation. You can think of it like a russion doll. The outmost element / doll is called the “root element”. There can be only one of those, i.e. there’s only one tree but you can have multiple branches. Further down the tree, you can have sibling elements (like in the example in the image). There are names for all the different relationships between elements in the hierarchy such as “sibling”, “parent”, “ancestor” or “descendant” and so on.
Each element has a start tag (<test>), and end tag (</test>) and some content in between. Think of it like an oreo cookie. If the element is empty, it can looks like this too: <test/>. Elements can also have attributes, shown in orange in the example. When talking about attributes, we write them like so: @rend meaning “the rend attribute”. Let’s look at an example.
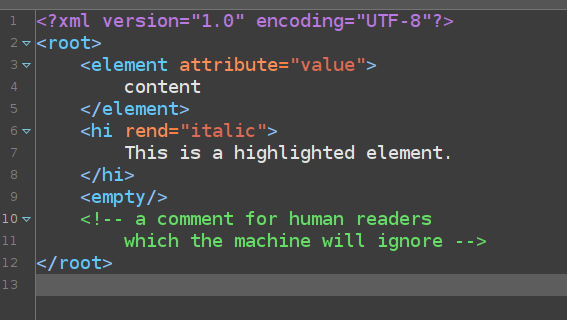
<root> here, though it will likely be called <TEI> or sth else for you. The elements <element> and <hi> are siblings. The <hi> element has an attribute, @rend with the attribute value “italic”. The element content is the text “This is a highlighted element”. However, since XML only conveys meaning, not actually style information, “highlighted” is just a word here. If you actually want the text to be represented in italics, you need to transform your document into an output format. Having all the meaning coded in XML which is later transformed for representation in different formats is called the single source principle. Of course, you can also nest elements, so elements can contain both text (like in the examples) and other child elements (not shown in the example). You should also know that some characters need to be “escaped” in XML. For example, an ampersand (“&”) character needs to be written like so: &. If you don’t do this, XML will get angry at you 😉
There are rules on how you can name your elements. You can read up on them if you want to know but I won’t discuss them here. A playful exercise I often use with my students for exploring naming conventions and sources for errors is the following: Simply find 5-10 ways to break it. Just know that XML is case-sensitive (i.e. <ninja>, <Ninja> and <NINJA> are not the same). By convention, we mostly use camelCase (<latexNinjaBlog>).
There are two more terms you need to know: If a document follows the rules, i.e. if it is correct XML, we call it well-formed. Futhermore, you can link a schema (such as the Text Encoding Initiative standard) to your document, then you also need to check / a validator can check if your document is also valid according to this standard. Your editor will have a functionality to check this (see the image for an example in Oxygen XML and more on XML editors later).

.xml!What’s next? Learning a standard relevant to you, such as TEI
Practice but also, maybe best familiarize yourself with the XML standard you’ll likely be using. If you don’t know which one, use the Text Encoding Initiative (TEI) first. That way, you’ll learn the relevant element names rightaway. It’s great that XML let’s you invent your own element names but in the end, you will likely only be working with existing XML standards if you’re in the Digital Humanities.
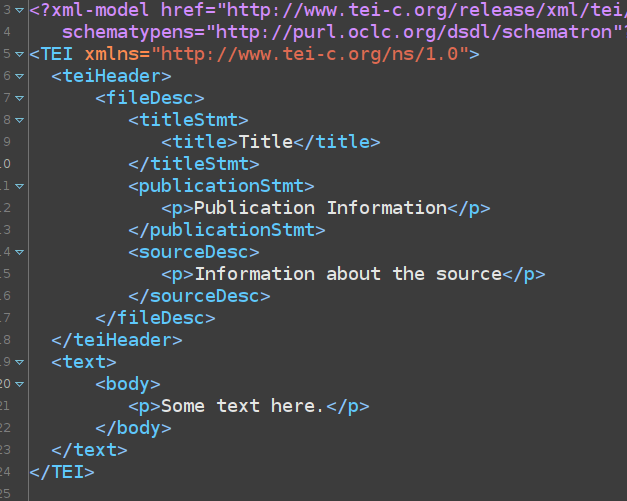
<teiHeader>) with, in the very least, the elements included here.If you want to create a document in the TEI standard in Oxygen, choose “TEI all” when prompted to select document type upon creating a new file. It will automatically have the TEI schema included in the correct way. This gives you access to documentation (hover over element names to access it – click link in the tooltip for more; type < and the editor will suggest elements which make sense / are allowed to add at your cursor’s current location) but will also give guidance if you make a mistake. This will be shown underlined in red and usually, there is some (more or less helpful) error message to help you resolve the problem.
To check whether your document is well-formed (correct XML strucutre) and valid (correctly following the selected/linked standard), click the validation icon in Oxygen XML.
If you want to know what elements to use in TEI to encode your specific document type or to find documentation about certain elements and attributes in the TEI, just google “TEI [your problem]”. You will find definitions pages, examples pages and more general references. That’s really all you need to know for now. Learning the TEI is getting to know the elements and modules relevant to you – just like learning vocabulary. No magic involved. Just familiarize yourself with what you need when you need it.
Some of the most important elements to read up on are: The TEI Core module in general, <teiHeader>, <div>, <p>, <ab>, <head>, <hi>, <persName>, <placeName>, <date>. But by all means, please don’t learn anything by heart. It’s enough to look at the definition and 1-3 examples for each one. Research more only as needed.
You can also try some predefined conversion pipelines (stylesheets) via the Oxgarage web tool. Try out converting a MS Word .docx which uses macros/templates to TEI-XML.
Some practicalities
Now that you (hopefully) understood XML, you might want to try it out or use it for your work. For that, you will need an XML editor. At my workplace, we have a licence for the Oxygen XML editor which seems to be quite widespread in the Digital Humanities. Christoph Schöch has recommended the use of the Atom editor (which I use for programming but not necessarily XML) with plugins to replace the neither free nor open Oxygen software. Knowing just how to use an XML editor is not really necessary in detail, since you won’t be doing much yet. Things like how to set up an XSL transformation will maybe follow in a designated XSLT tutorial in the future (there already is a video about it in my German XSLT course).
A cool trick to know: Select some text, then press CTRL+e to add markup/an element around it quickly. Maybe learn the basics of Regex Search-and-Replace to speed up your annotation process.
Phewww, this got way long for a supposedly super short tutorial. Of course, I could have just mentioned the most important snippets but I guess this post is kind of wholesome in a way that you will have all you need to get started.
Let me know how it’s working for you.
And as always, thanks for all the fish!
Ninja over and out 😉
Further resources
- W3C XML Tutorial (highly recommended)
- What is XML and why should humanists care? An even gentler introduction to XML (really quite long compared to this blogpost)
- The TEI’s Gentle Introduction to XML (really quite long too)
- A great into to the most important TEI elements for doing transcriptions is this: https://andrewdunning.ca/transcribing-medieval-manuscripts-tei
- The TEI’s own primers (such as 11 Representation of Primary Sources) are great, of course, but maybe a tad too exhaustive if you’re learning about this for the first time. But as you might know, I don’t generally approve of using documentation or reference like documents for teaching purposes. It might seem tempting to think your documentation would be a great “2 in 1” but it really isn’t. Believe me. Maybe rather search for a tutorial for your specific use case at first.
- Read up on some theory, like the single source principle: Patrick Sahle, What is a Scholarly Digital Edition? in: Digital Scholarly Editing: Theories and Practices (Driscoll and Pierazzo eds.), Open Book Publishers 2016. http://dx.doi.org/10.11647/OBP.0095.02
- In German: IDE School slides & IDE Kurzreferenz
- In German: my teaching video TEI-Annotation in Oxygen XML: Von den Basics zur Automatisierung mit regulären Ausdrücken on Youtube
Buy me coffee!
If my content has helped you, donate 3€ to buy me coffee. Thanks a lot, I appreciate it!
€3.00

“given it’s simple text file based nature” should be “given its simple text file based nature”. Or actually, to avoid four adjectives in a row before we find out what the noun is, even better would be “given its simple nature based on text files”.
LikeLike