Fine-tuning Machine Learning with Humanities Data: Creating Ground Truth Annotations (i.e. Labeled Data)
As most of us will probably know by now, machine learning has become a big part of digital humanities projects,

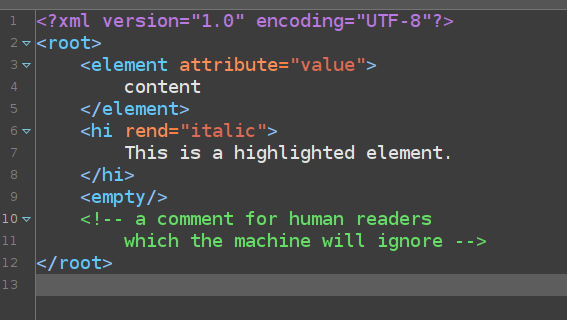
A small category for a big subject in the DH: XML and Annotation ;)
As most of us will probably know by now, machine learning has become a big part of digital humanities projects,
In an earlier post, I described the considerations that go into creating a training dataset for Computer Vision, including how
In 2017, I had an internship at the German Historical Institute in Paris, where my task was to annotate around 1,200 regests. My job was to get them from source data in a Word document to TEI-XML in the end, but the project requirement was to keep everything in Word as long as possible. So, the annotations had to be done using Formatvorlagen (which I believe is called ‘macros’ or ‘stylesheets’ in English). In this post, I want to reflect on what helped me finish the annotation in three weeks (when previous estimates were that it would take about a year). Even if your project is different from this setup, these learnings may help you make your own annotation projects more efficient. Back then, I wrote a tutorial for people in the project who might want to continue my approach after I was gone. It’s in German but you can use LLMs to translate it for you if you’re interested.
Understanding the material aspects of historical books is crucial. Unlike modern books, copies from the same print run of historical
read more Why Do We Need to Digitize the Materiality of Pre-Modern Books?
Today’s post is a short introduction to digital scholarly editing. I will explain some basic principles (so mostly theory) and point you to a few resources you will need to get started in a more practical fashion. I’m teaching a class on digital scholarly editing this term, so I thought I could use the opportunity to write an intro post on this important topic. How does a Digital Edition relate to an analogue scholarly edition? Unlike analogue scholarly editons, digital editions are not exclusive to text and they overcome the limitations of print by following what we call a digital paradigm rather than an analogue one. This means that a digital edition cannot be given in print without loss of content or functionality. A retrodigitized edition (an existing analogue edition which is digitized and made available online), thus, isn’t enough to qualify as a digital edition because it follows the analogue paradigm. Ergo: It’s not about the storage medium. A
read more What you really need to know about Digital Scholarly Editing
Today’s post is my long-awaited take on typesetting scholarly editons using the reledmac package. Not only does it introduce the
read more Enough reledmac to be dangerous: Scholarly Editing with LaTeX & XSLT
It’s been awfully quiet on this blog but actually, there’s lots of Ninja activity going on right now: I’m excited to announce that I will give the first ever official LaTeX Ninja workshop, in person at Harvard in about two weeks! It’s called “Beyond TEI: Digital Editions with XPath and XSLT for the Web and in LaTeX”. (Apart from that, there’s a short book review coming up in TUGboat.) Since there probably are a good number of people who would be interested in such a workshop but can’t attend in person, I will share the slides and teaching materials on Github later on. That way, they can be reused for self-study. This blogpost gives somewhat of an outline of the contents of the workshop and contains links to related posts on this blog. Participants might want to read some of them in preparation or as an additional resource. [Get to the github repo with all the materials (`additional resources’ directory)
As some of you might know, I have been promising to provide an intro to XML for a long time.
read more A shamelessly short intro to XML for DH beginners (includes TEI)
Since you all probably already know that I’m a bit short on time but trying to keep this blog alive
read more Teaching Materials: A German intro class to XPath and XSLT
As per request, I wanted to address the subject of JATS-XML to LaTeX transformations today. The post might be interesting for you still even if you’re not particularly interested in said transformation since it will address more general requirements for transformations as well. What is JATS-XML and why would we transform from and into it? First things first: What is JATS-XML? It is an XML standard called the Journal Article Tag Suite (JATS). Journal Article Tag Suite … is an application of NISO Z39.96-2019, which defines a set of XML elements and attributes for tagging journal articles and describes three article models. The content on this site is the supporting documentation for the standard. JATS is a continuation of the NLM Archiving and Interchange DTD work begun in 2002 by NCBI. (source & JATS documentation) It has the <article> element, and in that, you get <front>, <body>, and <back>. Learn more about it and see examples in the links.
The title suggests a political discussion, however, this is not what I want to discuss here. (However, I had a ‘more political’ discussion planned for a while.) At a recent conference, I realized many people from the Humanities find it difficult to grasp what the DH even really are – because they are so diverse. I was told a colleague had gone to a short DH summer school but still feels like she doesn’t get what the DH really are. Or that she hasn’t learned any ‘real DH’. How does this happen? How can we make it better? Maybe, as a first step, by trying to answer what the DH are in a way which is easy to grasp for someone who isn’t already part of the DH: It is really an umbrella term for a wide range of topics ranging from digital edition to long-term archiving, digitizing facsimile scans of books or running analyses. I don’t promise to unveil
read more What are ‘real’ Digital Humanities and how to get started?
Annotation is a fundamental part of the DH. But often, us DH people don’t actually do the annotation. We do
read more Automating XML annotation: Get more done using RegEx Search&Replace and xsl:analyze-string
My non-DH colleagues and friends ask me more and more often if I think they should start doing Digital Humanities and if yes, where to start? Since this seems to be an interesting topic for many, I thought I’d quickly elaborate on it. Disclaimer: Even though I’ll put on my “career advisor” hat right now, I want to remind you that I am in no way qualified to advise you on your career. So if it all goes downwards from now, I am not the one to blame. All opinions are my own and should be treated as such. So, now we got the legal part over with (essentially: don’t sue me), let’s get to my opinion on the topic. I think it is out of the question whether you should start doing DH. In my prognosis, almost all Humanities research is going to be at least part DH in the near future. If you ask me. And you did.
Today, I wanted to share this super simple XML to LaTeX tutorial. Using XSLT, you are going to transform XML data to LaTeX output which you can then go on to compile into your desired output PDF. There will be no fancy stuff whatsoever in this post, just the basics and what to keep in mind with these transformations. It is the quick intro to XML to LaTeX I did with my students a while ago which was done one day after they had their first contact with XSLT, so it should really be beginner-friendly. I labeled it “Advanced LaTeX” anyway because I think starting to automate things is always a step in the right direction 😉 Edit March 2022: Sadly, with WordPress changes (and source code support never working all that well to begin with), the code formatting of this post is pretty broken. Since it tends to re-break soon after I fix it, here is a similar /